

关键词检测(keyword spotting, KWS),即我们通常所说的语音唤醒,指的是一系列从实时音频流中检测出若干预定义关键词的技术。随着远讲免提语音交互(distant-talking hands free speech interaction)技术的发展,关键词检测及其配套技术也变得越来越重要。类比于人和人交互时先喊对方的名字一样,关键词就好比智能设备的"名字",而关键词检测模块则相当于交互流程的触发开关。
针对各类AIoT应用来说,由于需要在硬件条件有限的设备端对音频流进行实时监听,所以关键词检测模块必须做到"低资源、高性能"。所谓低资源,指的是全套算法所需的算力、功耗、存储、网络带宽等资源应当做到尽量节省,以满足实际设备硬件条件的限制;而所谓高性能,则是要求智能设备在包含各种设备回声、人声干扰、环境噪声、房间混响的实际应用场景中也能具有较高的唤醒率和较低的虚警率,同时具有较小的唤醒事件响应延迟。针对实际场景中各种不利声学因素的影响,只靠关键词检测本身是无法应对的,所以关键词检测技术一般需要配合语音增强(speech enhancement)技术来使用,并且语音增强和关键词检测还需要实现匹配训练和联合优化才能发挥出更好的性能表现。
本项目以你好米雅等开源数据集为基础,提供了一种基于盲源分离(blind source separation, BSS)理论框架的语音增强方法,以及一种可扩展的多通道关键词检测与通道选择模型。同时还提供了配套的数据模拟,模型训练以及测试工具链。该模型参数量为123k,适合于低资源嵌入式应用。并且该模型还实现了和语音增强算法的匹配训练,进一步提升了模型在实际系统中的性能。
本项目的总体框架如图1所示,其中主要分为语音增强和关键词检测两个部分。首先,语音增强模块以多通道麦克风信号和单路参考信号r为输入,经过去混响、回声消除、盲源分离、增益控制等操作后,输出多路分离后的信号。此时我们可以认为其中一路输出是包含"你好米雅"关键词信噪比较高的目标语音,而其它输出则是信噪比较低的噪声或干扰信号。之后多路信号经过关键词检测模块进行处理,检测其中的关键词音频,抛出唤醒事件,并选择关键词信噪比最高的通道,即n',供后续交互流程使用。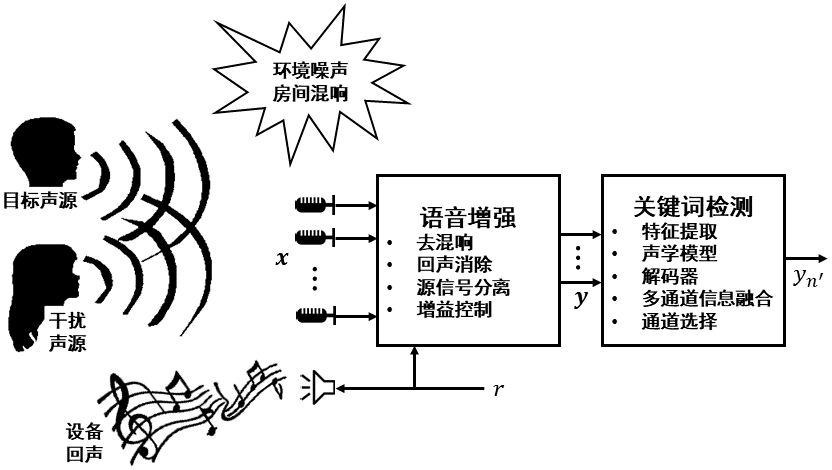
针对各类AIoT应用来说,由于需要在硬件条件有限的设备端对音频流进行实时监听,所以关键词检测模块必须做到"低资源、高性能"。所谓低资源,指的是全套算法所需的算力、功耗、存储、网络带宽等资源应当做到尽量节省,以满足实际设备硬件条件的限制;而所谓高性能,则是要求智能设备在包含各种设备回声、人声干扰、环境噪声、房间混响的实际应用场景中也能具有较高的唤醒率和较低的虚警率,同时具有较小的唤醒事件响应延迟。针对实际场景中各种不利声学因素的影响,只靠关键词检测本身是无法应对的,所以关键词检测技术一般需要配合语音增强(speech enhancement)技术来使用,并且语音增强和关键词检测还需要实现匹配训练和联合优化才能发挥出更好的性能表现。
本项目以你好米雅等开源数据集为基础,提供了一种基于盲源分离(blind source separation, BSS)理论框架的语音增强方法,以及一种可扩展的多通道关键词检测与通道选择模型。同时还提供了配套的数据模拟,模型训练以及测试工具链。该模型参数量为123k,适合于低资源嵌入式应用。并且该模型还实现了和语音增强算法的匹配训练,进一步提升了模型在实际系统中的性能。
本项目的总体框架如图1所示,其中主要分为语音增强和关键词检测两个部分。首先,语音增强模块以多通道麦克风信号和单路参考信号r为输入,经过去混响、回声消除、盲源分离、增益控制等操作后,输出多路分离后的信号。此时我们可以认为其中一路输出是包含"你好米雅"关键词信噪比较高的目标语音,而其它输出则是信噪比较低的噪声或干扰信号。之后多路信号经过关键词检测模块进行处理,检测其中的关键词音频,抛出唤醒事件,并选择关键词信噪比最高的通道,即n',供后续交互流程使用。

机构好评:96

